Содержание
Что важно учесть при составлении семантического ядра.
Как собрать правильное семантическое ядро
Если вы думаете, что собрать правильное ядро способен некий сервис или программа, то вы будете разочарованы. Единственный сервис, способный собрать правильную семантику, весит около полутора килограмм и потребляет около 20 ватт мощности. Это мозг.
Причем в этом случае у мозга есть вполне конкретное практическое применение вместо абстрактных формул. В статье я покажу редко обсуждаемые этапы процесса сбора семантики, которые невозможно автоматизировать.
Существует два подхода к сбору семантики
Подход первый (идеальный):
- Вы продаете заборы и их монтаж в Москве и Московской области.
- Вам нужны заявки из контекстной рекламы.
- Вы собираете всю семантику (расширенные фразы) по запросу «заборы» откуда угодно: от WordStat до поисковых подсказок.
- Получаете много запросов — десятки тысяч.
- Затем несколько месяцев чистите их от мусора и получаете две группы: «нужные» запросы и «минус-слова».
Плюсы: в этом случае вы получаете 100% охват — вы взяли все реальные запросы с трафиком по главному запросу «заборы» и выбрали оттуда всё, что вам нужно: от элементарного «заборы купить» до неочевидного «установка бетонных парапетов на забор цена».
Минусы: прошло два месяца, а вы только закончили работать с запросами.
Подход второй (механический):
Бизнес-школы, тренеры и агентства по контексту долго думали, что с этим делать. С одной стороны, действительно проработать весь массив по запросу «заборы» они не могут — это дорого, трудозатратно, людей не получится научить этому самостоятельно. С другой стороны, деньги учеников и клиентов тоже надо как-то забрать.
Так было придумано решение: берем запрос «заборы», умножаем на «цены», «купить» и «монтаж» — и вперед. Ничего не надо парсить, чистить и собирать, главное — перемножить запросы в «скрипте-перемножалке». При этом возникающие проблемы мало кого волновали:
- Все придумывают плюс-минус одинаковые перемножения, поэтому запросы вида «монтаж заборов» или «заборы купить» моментально «перегреваются».
- Тысячи качественных запросов вида «заборы из профнастила в Долгопрудном» вообще не попадут в семантическое ядро.
Подход с перемножениями себя полностью исчерпал: наступают трудные времена, победителями выйдут только те компании, которые смогут для себя решить проблему качественной обработки действительно большого реального семантического ядра — от подбора базисов до очистки, кластеризации и создания контента для сайтов.
Задача этой статьи — научить читателя не только подбирать правильную семантику, но и соблюдать баланс между трудозатратностью, размером ядра и личной эффективностью.
Что такое базис и как искать запросы
Для начала договоримся о терминологии. Базис — это некий общий запрос. Если вернуться к примеру выше, вы продаете любые заборы, значит, «заборы» — главный для вас базис. Если же вы продаете только заборы из профнастила, то вашим главным базисом будет «заборы из профнастила».
Но если вы один, запросов много, а кампании надо запускать, то можно взять в качестве базиса «заборы из профнастила цена» или «заборы из профнастила купить». Функционально базис служит не столько как рекламный запрос, сколько как основа для сбора расширений.
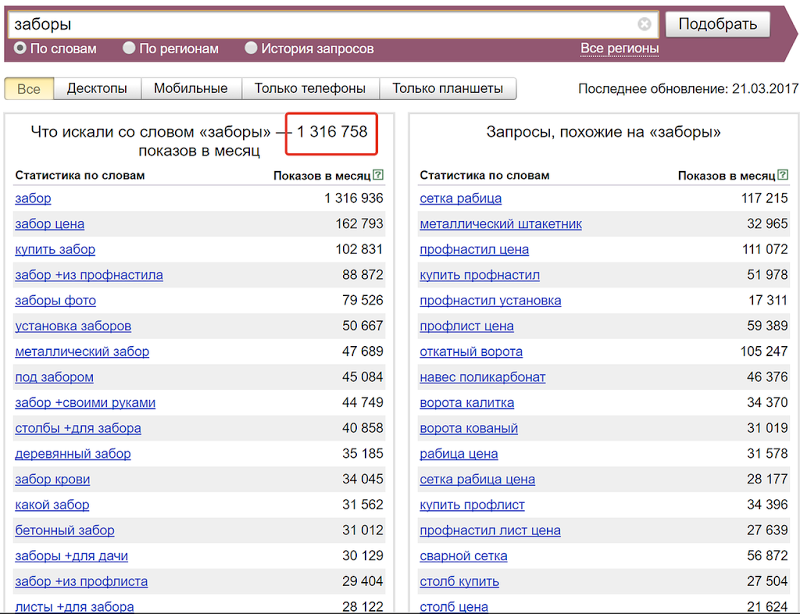
Например, по запросу «заборы» более 1,3 млн показов в месяц по РФ.Это — не пользователи, не клики и не запросы. Это количество показов рекламных блоков «Яндекса» по всем запросам, включающим слово «заборы». Это мера охвата, применимая к некоему большому массиву запросов, объединенных вхождением в него слова «заборы».
В то же время по запросу «заборы из профнастила» — только 127 тысяч показов, то есть охват сжался в десять раз. Сопоставимым образом уменьшится и количество запросов, и трафик на сайт.
Таким образом, можно сказать, что базис — это общий запрос, описывающий товар, услугу или нечто иное, за счет самой своей формулировки определяющий меру охвата потенциальной аудитории.
- Хотим «геноцида» конкурентов — берем огромный массив запросов по базису «забор», несколько лет его чистим и группируем — и вуаля — у вас лучшая рекламная кампания на рынке.
- Хотим сделать скромно, но эффективно, продавая только высокомаржинальные заборы из профнастила ограниченной аудитории — берем меньшую в десять раз выборку по запросу «заборы из профнастила» и работаем только с ней.
Итак, первый этап любой рекламной кампании — подбор семантики. А первый этап подбора семантики — это подбор базисов. Важно подобрать базисные запросы, которые:
- Описывают товар или услугу.
- Дадут такой объем расширенных запросов, который вы можете обработать в приемлемые для себя сроки.
Теперь попробуем разобраться с проблемой поиска базисов как таковых.
1. Как вы сами называете товар или услугу
Если вы — подрядчик, то спросите об этом у клиента. Например, заказчик говорит вам: «Я продаю спортивные покрытия в Москве и области». Выбросьте из формулировки заказчика Москву и область, а также подберите синонимы.
Базисы в таком случае будут такими:
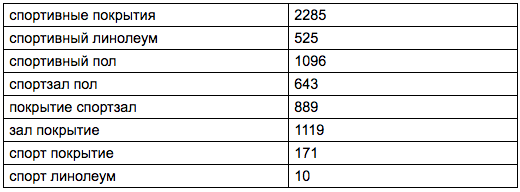
Цифры — это данные частотности по Москве и области по WordStat. Нетрудно заметить, что каждый из запросов при парсинге WordStat в глубину даст разную выборку расширенных запросов, и каждая выборка — это сегмент целевого спроса.
Пример с синонимами посложнее: «небольшой» медиаплан на сотню с лишним базисов с частотностью по Москве для продажи элитной недвижимости:
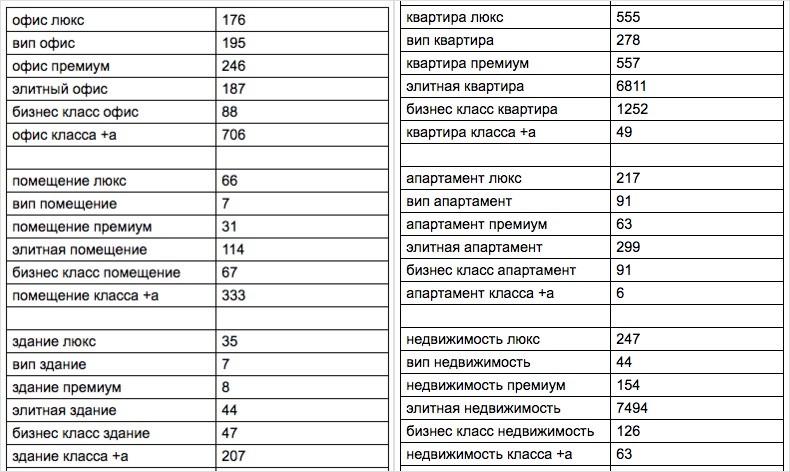
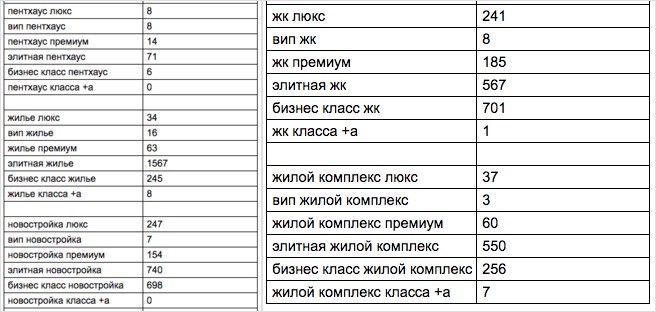
Вывод: собирать семантику сложно. Но сам сбор низкочастотных запросов довольно прост — есть куча сервисов от Key Collector до MOAB и других. Дело не в сервисе. Дело в том, что подобрать корректные базисы сервисом невозможно — это можно сделать только руками и мозгом человека, это самая трудная и тяжелая операция.
Итак, мы уже вспомнили определения товара или услуги «из головы» и привели их к укороченным формам. То есть если мы продаем «грузовики камаз», то пишем в файл просто — «камаз».
2. Посмотрите сайты конкурентов
Важно понять ключевой принцип — выборка по запросу «камаз» и по запросу «камаз -65115» дает разные запросы, частично непересекающиеся. Это разные сущности.
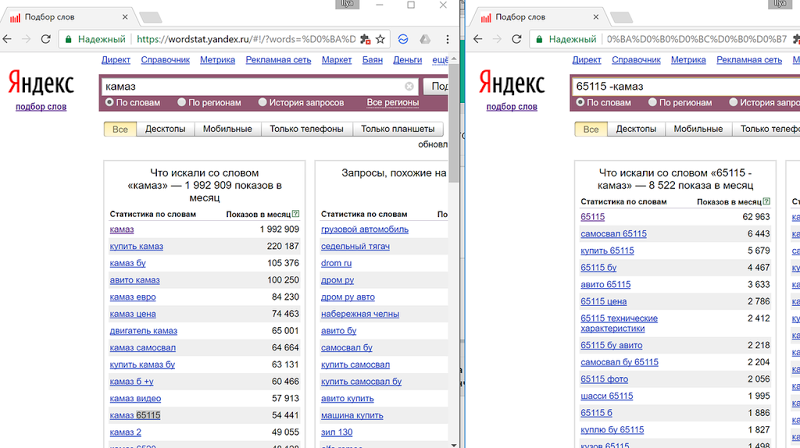
Поэтому не нужно мучительно читать тайтлы конкурентов или анализировать их в сомнительных сервисах. Расслабьтесь, включите фантазию и почитайте сайты конкурентов. Вот список артикулов, каждый из которых — отдельная выборка.
3. Сервисы поисковых систем
Здесь буду краток: проверяйте найденные в первых пунктах базисы вручную через правую колонку WordStat и блок «искали вместе с этим»
Пример: в правой колонке WordStat содержатся так называемые запросы, которые пользователи искали вместе с указанным. Глядя на правую колонку по запросу из примера выше, можно увидеть запрос с вхождением слова «самосвал».
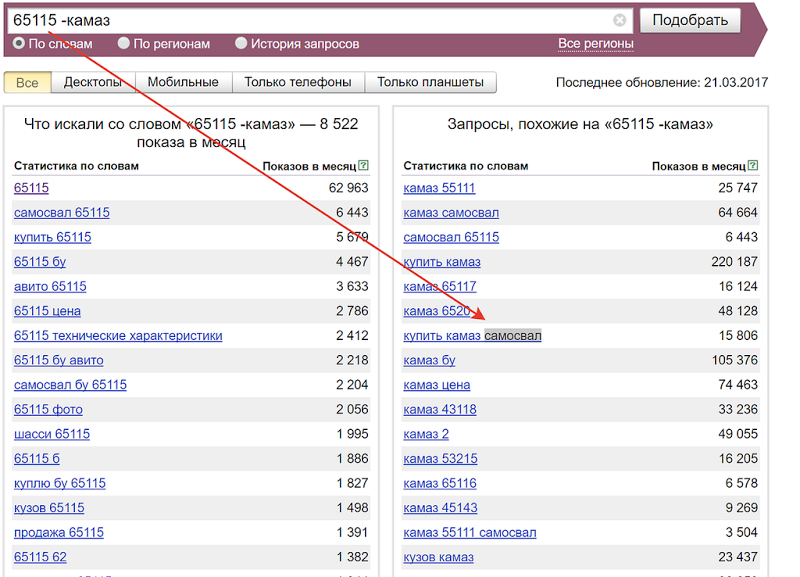
Отлично. Запрос «купить камаз самосвал» нам не нужен, так как он и так попадет в расширенные запросы по базису «камаз», а вот запрос «самосвал» — это новый сегмент с отдельными новыми запросами, новым спросом и новой семантикой.Берем его в проект. Аналогичным образом анализируем и блок «искали вместе с этим» в выдаче «Яндекса» и Google.
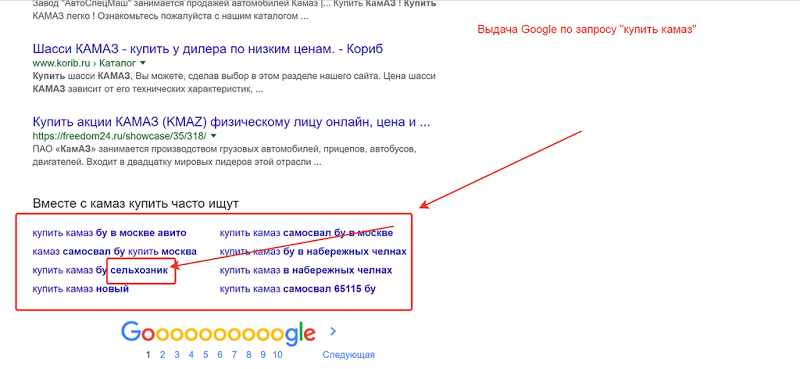
Google, к примеру, подсказывает запрос «сельхозник»
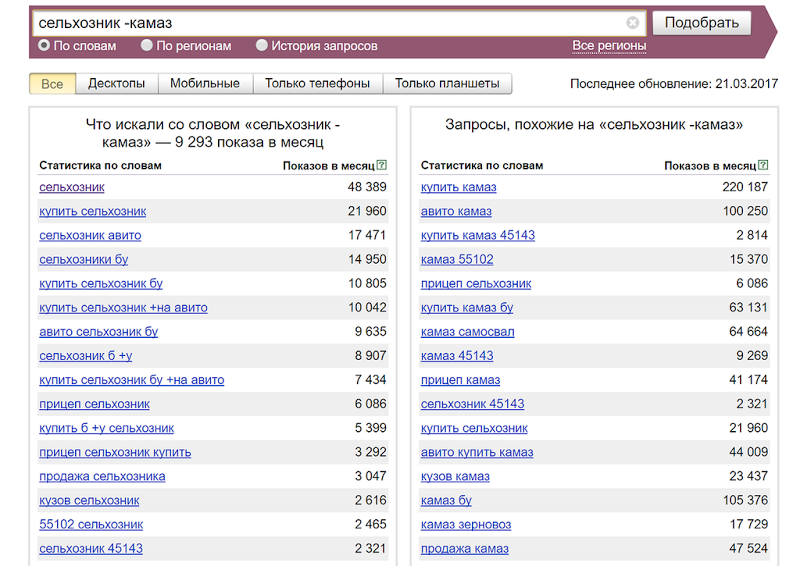
Вот что можно получить по нему в WordStatПроверим, что говорит «Яндекс». Даже если предположить, что вы не продаете ничего, кроме «КамАЗов», то ваши усилия все равно не пропадут даром.
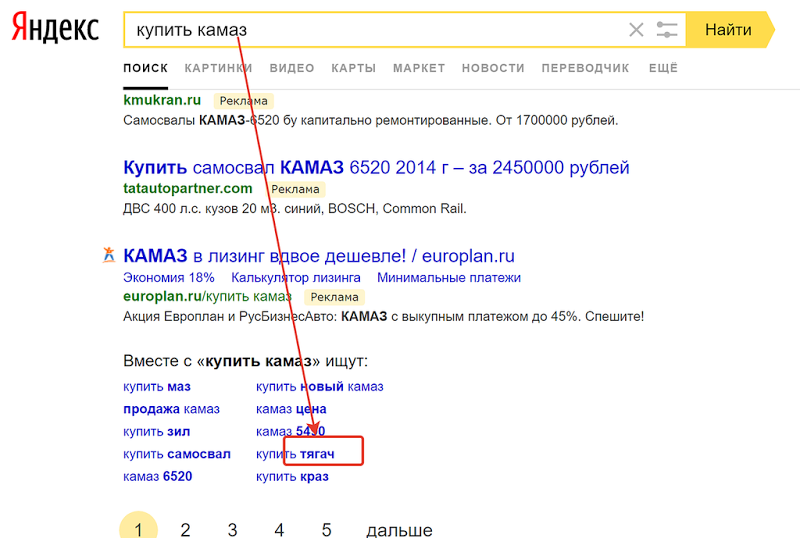
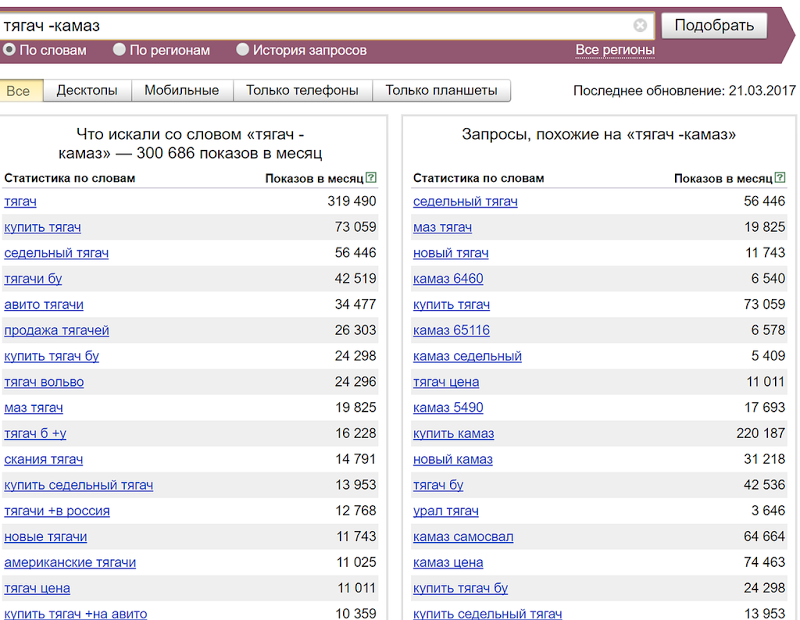
Можно взять запрос «тягач» и получить новый спрос на ваши грузовики и по немуВ целом, думаю, принцип понятен: задача — найти как можно больше целевых базисов, которые выступают инициаторами, драйверами новых длинных семантических хвостов.
Конечно, тут можно дать ещё много советов: посмотреть анкор-файл конкурентов, посмотреть выгрузки из SpyWords или Serpstat. Всё это, конечно, хорошо. Вернее, было бы хорошо, если бы не было так грустно. Потому что в сущности работа еще даже не началась: насобирать каждый может, а попробуйте-ка всё это очистить, сгруппировать и грамотно управлять.
Вышеописанного вполне достаточно, чтобы, имея светлую голову, собрать семантику на порядок качественнее и лучше, чем у 99% ваших конкурентов.
Как не потратить всю жизнь на сбор ключевых слов
Многие спрашивают: как грамотно управлять семантикой, как её «резать». Если вы продаете могильные камни из буйволиного рога в Нарьян-Маре, вы вряд ли столкнетесь с этой проблемой — у вас семантики всегда будет мало. В то же время, в «горячих» популярных тематиках семантики всегда валом: названия брендов, категорий, моделей, их синонимы и так далее.
Мы решаем эту проблему за счет многоуровневой приоритизации семантики.
1. Приоритизация семантики до сбора запросов
Посмотрите на разделы и категории, по которым собираете семантику, оцените среднюю маржинальность каждой категории. Выкиньте те разделы, где маржинальность меньше 20%. Чаще всего (почти всегда в b2c и чуть реже в b2b) на марже 20% вы будете крутить рекламу в ноль.
Если всё равно остается много — уберите и те разделы, где маржинальность меньше 25-30%, там вы тоже, скорее всего, много не заработаете — максимум немного мелочи в карман плюс покажете производителю больше оборота и выбьете новые скидки. Зарабатывать интересные деньги получается на товарах и услугах с маржой от 30% — не всегда и не везде конечно, но эти цифры я видел десятки раз на самых разных проектах.
2. Сбор базисов и расширенной семантики по ним
Собрали? Все равно получается много? Проранжируйте запросы. Ставьте 1, 2 или 3 рядом с каждым базисом. Заставьте себя это сделать, вот так:
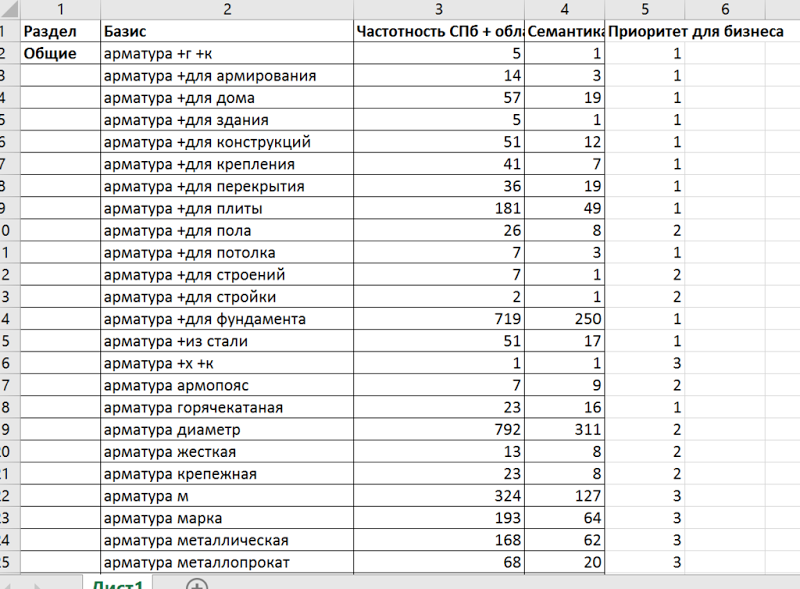
Я специально ограничиваюсь тремя значениями — это просто. Если у вас будет десять уровней приоритета, вы сойдете с ума, думая о том, поставить 6 или 7 конкретному базису, — а так решения очень простые и очевидные.Кроме того, это помогает структурировать свой бизнес для самого себя — взглянуть на него сквозь призму спроса и маржинальности: фильтруем по столбцу «Приоритет» и видим, что поставили «1» тем базисам, по которым мало спроса.Значит, надо либо активнее работать с другими товарными направлениями, снижать закупочные цены, либо стимулировать спрос — но это уже другая история.
3. Отсекли всё неприоритетное и всё равно семантики слишком много
Когда говорят про «резать» семантику, те, кто с этим поработал, как правило, имеют в виду удаление низкочастотных запросов с частотностью ниже определённой отсечки. В тематических дискуссиях в Facebook и на форумах я регулярно вижу цифры от 5 до 10 (имеется в виду общая частотность по запросу).
То есть намеренно убирается из массива всё, что по частотности меньше 10.
Понятно, что так делать можно, если у вас всё равно очень много семантики. Но это всегда вопрос выбора между поеданием рыбы и сидением на неудобных для сидения предметах. Слишком много уберете — недосчитаетесь каких-то минус-слов, получите больше «грязного» трафика на запуске, но выиграете в трудозатратности.
Моё мнение таково: условная точка баланса здесь находится на уровне «убираем всё, что не имеет частотности». Это позволяет выкинуть примерно половину массивов, полученных из различных источников, в то же время трафик на запуске остается очень чистым, с погрешностью буквально 1-3% и быстро дочищается.
Что значит «дочищается»
Представьте, что вы собрали рекламную кампанию для поискового размещения в «Яндекс.Директе», запустили ее, и вам нужно оценить эффективность проделанной работы. Как это сделать? Оценивать по продажам? Не совсем правильно, ведь продажи — это результат работы цепочки «кампания-сайт-менеджеры». Звонки? Тоже нет, ведь огромное влияние на количество звонков оказывает сайт: может быть, с кампанией всё хорошо, просто сайт сделан неправильно.
Быстро проверить эффективность поисковой кампании можно в «Яндекс.Метрике». Для этого нам надо через два-три дня после запуска кампании получить отчет о фразах, послуживших источниками перехода. Как найти этот отчет в «Метрике»:
А затем:
Кликаем на крестик на всех группировках, кроме «Поисковая фраза», и нажимаем «Применить». Мы получим отчет о тех фразах, по которым пользователи увидели наши объявления, кликнули по ним и перешли к нам на сайт. Что делать с этим отчетом?Внимательно просмотреть и выделить нерелевантные фразы, которые не относятся к вашему бизнесу. На жаргоне их называют «мусором». В профессионально сделанных кампаниях в первое время после запуска доля «мусора» может составлять от 1 до 4%, в кампаниях, собранных «на коленке», — до 20-40%.
Как вы уже, наверное, поняли, процедуру с дополнительной очисткой от мусора стоит проводить регулярно — как минимум, два-три раза в месяц. Почему так часто?
У нас был интересный пример из практики. Мы работали с кампанией, в которую включили для клиента высокомаржинальный запрос «черный дым дизель». Клиент работал с дизельными двигателями, и такой запрос означает, что у клиента есть серьезная проблема с двигателем, и, вероятно, потребность в квалифицированных услугах.
Одновременно с этим в сентябре 2016 года, когда группировка российского флота направилась в Сирию, ТАКР «Адмирал Кузнецов» привлек внимание международных СМИ сильным черным дымом из выхлопной трубы. Это неизбежно спровоцировало запросы вроде «черный дым дизель адмирал кузнецов».
Ранее таких запросов просто не было, поэтому и не было минусов формата «–адмирал, –кузнецов». Поэтому мало того, что наше объявление показалось по таким запросам, так оно ещё и сгенерировало бессмысленные переходы, не имеющие для бизнеса никакой ценности.
Отследить такие запросы оперативно можно только в «Метрике»: поэтому возьмите себе за правило на старте кампании почаще (позже — реже) проверять семантику и дополнительно минусовать новый мусор.
Разумеется, возникает вопрос: а что вообще влияет на количество мусора. Всё просто — статистическая достоверность семантики.
На что влияет объем семантики
Далеко не всегда люди понимают, о чем говорят, когда обсуждают влияние обширного семантического ядра на цену клика, качество кампании и прочее. Сама по себе обширная семантика не вызывает ни снижения цены клика, ни увеличения качества кампании. На что же реально влияют сотни и тысячи собранных НЧ-запросов?
1. Чистота трафика на запуске кампании
Чем больше запросов вы соберете — тем больше найдете минус-слов. На бесконечно большой выборке запросов вы найдете все возможные минус-слова, потратив на это бесконечный период времени.
На практике стоит ограничиться запросами, как я уже говорил, с частотностью от 1 по нужному региону — это даст «мусорность» в районе 3-4% при запуске, после чего вы быстро дочистите оставшиеся мусорные запросы, минусы, по которым почему-то не попали в выборку.
При этом стоит использовать и WordStat, и советы поисковых систем, собирая подсказки для каждого запроса, полученного в WordStat. Использование одного только WordStat даст высокую мусорность — 10-15% на запуске как минимум (если не больше). Но все мы понимаем — чем больше мусора, тем больше расход средств, тем меньше лидов на единицу расхода.
2. Релевантность объявлений запросам
Здесь важно понять системообразующий принцип: запросы, которые вы добавили в кампанию, по большому счету, ничего не значат. Они не важны.
Реальный трафик, который будет попадать к вам на сайт, приходит большей частью не по тем запросам, которые вы добавили в кампанию, а по расширениям от них. На один запрос, добавленный в кампанию, приходится как минимум три-четыре расширенных варианта — это ультра-НЧ, которые вообще никак не предскажешь, пользователи генерируют их прямо в момент поиска.
Поэтому не столь важен сам запрос: так много стало трафика по ультра-НЧ с частотой перехода в один-два раза в месяц или в год, что привязываться к конкретному запросу нет смысла. Важно собрать статистически значимую семантику, разбить её на мелкие группы похожих запросов и составить под них объявления.
Больше семантика — больше групп, больше точность соответствий и ниже цена кампаний на поиске. В конкретной группе похожих ультра-НЧ, из которых сформируется объявление, может быть пять-десять запросов — а если вы выудите из «Метрики» фразы по этому объявлению через полгода, получите список на 30-40 фраз как минимум.
Повторюсь: семантика — не панацея от всего и не божество. Семантика влияет на многое: на чистоту трафика, на релевантность объявлений запросам — но не на всё. Не имеет смысла собирать огромные выборки «нулевок» в надежде получить трафик дешевле — этого не будет.
Семантика влияет:
- На охват рекламной кампании.
- На чистоту трафика.
- На релевантность «запрос-объявление».
Вот те факторы, про которые вам стоит помнить в первую очередь. Впрочем, попробуем суммировать итоги в двух словах.
Кратко
- Соберите базисные запросы — общие фразы, описывающие ваши товары и услуги.
- Проверьте, все ли синонимы и переформулировки вы собрали: в помощь вам WordStat и блок «похожие запросы» в SERP.
- Соберите расширения по полученным запросам: WordStat, поисковые подсказки, база MOAB — всё идет в дело.
- Составьте табличку, где рядом с каждым базисом будет указана его частотность и количество расширенных запросов.
- Если запросов слишком много, и вы не успеваете их обработать — выполните приоритизацию базисов в зависимости от маржи, частотности и количества запросов.
- Окончательный семантический план сформирован. Теперь дело за очисткой и кластеризацией семантики.